I have often found a need to generate a sequential number list for a query, or at least that it would make the solution easier. This post looks at a way of achieving this. We’ll start with the premise that we need to generate a sequential number list starting from a specific number and of specific length. As a result of this assertion we need to be able to pass in these parameters.
The easiest way to solve this problem is to store a list of numbers in a table. This is surely simple and effective, the main drawback being we don’t know the numbers we’re going to need up front. If we use bigints anywhere in our code base we might need to cover off the entire range which means storing bigints from min to max. That would require a lot of storage space and may not be feasible. We will therefore look at another method. The main point being that I wish to generate these numbers on the fly. This in itself presents an issue which I will mention at the end of this post.
Lets start with something simple like the query below and build on it: –
[code language=”sql”]
select row_number() over(order by a.object_id)
from sys.all_columns a;
[/code]
This generates a fairly simple plan that is also very efficient. However unless we already have a huge number of columns this is severely limited in the size of result set returned. We can of course use a cross join back to the same DMV again to generate a larger list. This works however may not encompass the entire range we want (ie, not enough numbers generated) and there are more issues if we join this DMV more than twice. Let’s take a look at what happens. If we cross join this DMV twice or more (Four times here – please note that I am only using commas for brevity here, this is considered bad practice and doesn’t make it into my production code) then we start to see a sort operator in the execution plan: –
[code language=”sql”]
select row_number() over(order by a.object_id)
from sys.all_columns a,
sys.all_columns b,
sys.all_columns c,
sys.all_columns d,
sys.all_columns e;
[/code]
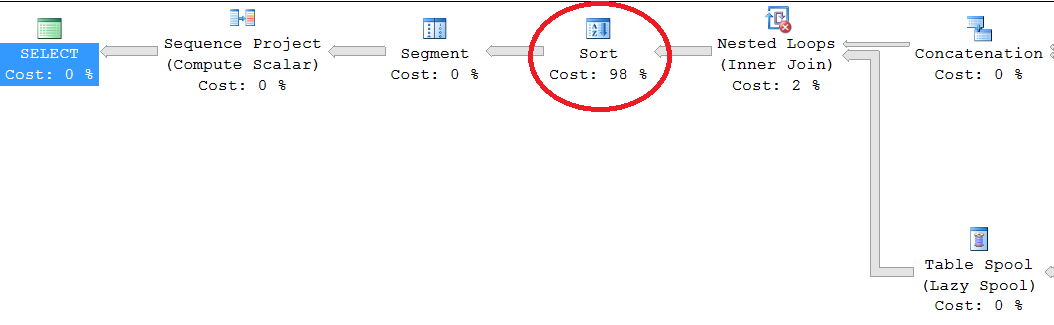
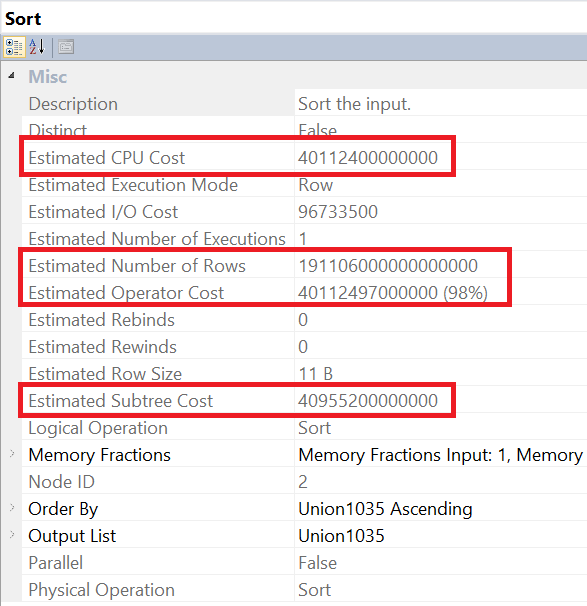
This sort operator presents a problem. A sort is a blocking operation which means that it must complete before we can return the result set to the next operator in the plan. Looking at the properties of this operator we can see that life is too short to wait for this complete.
We need to get rid of this operator, so lets play a simple trick on the opitmizer and make our lives a little easier. Rather than return a sorted list at this stage lets return all one’s. The optimizer is a pretty clever cookie a lot of the time and will realise that this won’t need to be sorted, a 1 cannot be determined to go before or after another 1 and be sorted. The downside is we don’t get our sequential numbers but that is a trivial problem to solve. So we have the below query (Which I won’t run, nor do I recommend it to you because the result set is massive).
[code language=”sql”]
select 1
from sys.all_columns a,
sys.all_columns b,
sys.all_columns c,
sys.all_columns d,
sys.all_columns e;
[/code]
Now we have removed the sort operator and we have a massive range of numbers to return. We’re most of the way there. Here is the new plan without the sort: –
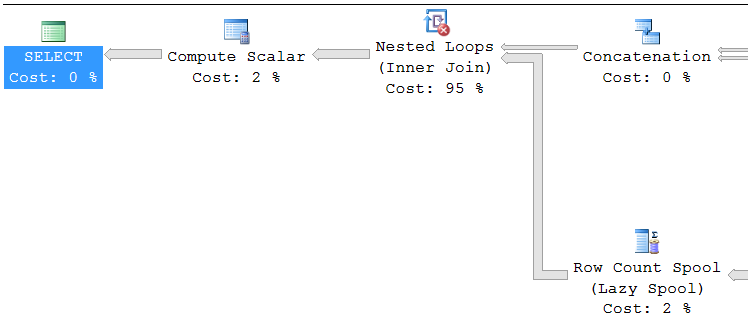
Ok the estimated cost is still huge and we’ve only got a massive list a one’s but lets solve both of those issues next. The great thing that we achieved by removing the sort operator is that we no longer have any blocking operators in our query plan. We can prove this by running the query. The select starts to return rows immediately, once you’ve confirmed this cancel the query because it takes too long to run and will most likely exceed execution memory. This is the case because when the query executes the select asks the next operator (The compute scalar) for a row to be returned. The compute scalar asks the loop join and so on and so forth until we get to the operators that are getting the rows. None of these operators block so the select is free to start returning rows as soon as we start the query. We can easily limit the result set with a top operator and we can get our number list back with the use of the row_number() function. To do so we just need to wrap the current result set returning it as a derived table. That would look like the below and we now have a query we can execute: –
[code language=”sql”]
select top (100000)
row_number() over(order by dt.i) as seq_no
from (
select 1
from sys.all_columns a,
sys.all_columns b,
sys.all_columns c,
sys.all_columns d,
sys.all_columns e
) dt (i);
[/code]
The plan that we get is also a lot nicer however because it’s of a decent size I suggest you look it over on your own computers. Now in this case I have used a specific top quantity but again this is trivial to sort. Lets create a function that gives us total flexibility here, also we’ll move the top operator for another slight efficiency gain: –
[code language=”sql”]
create function dbo.consecutive_numbers (
@top bigint
, @offset bigint
)
returns table
as
return
select row_number() over(order by v.i) + (@offset – 1) as number
from (
select top (@top) 1
from sys.all_columns a,
sys.all_columns b,
sys.all_columns c,
sys.all_columns d
) v (i);
[/code]
If we create this function, in say a “tools” database, we can then call it at any time to generate a numbers list. We can specify the required start point and the limit to be returned. Also because cross joining sys.all_columns 4 times generates a huge result set it is unlikely that we will exhaust the list of numbers we can generate. At any rate it’s far less likely than it is to exhaust our patience waiting for the result set to be returned. So if you don’t want to store a table to get at consecutive numbers then this might be a possible solution for you. I hope that this brief look at the optimizer proves useful to anyone looking for a solution to a similar problem. My final solution is presented below, it is almost identical but uses two inline table valued functions just because of the increased flexibility. Also I use just two cross joins because I wrote this for an OLTP environment. In case anyone is interested I did a speed run to compare the two variants and they were identical and only ever got to 33% CPU on my Surface Pro 3 so this is not hugely CPU intensive.
[code language=”sql”]
if object_id(N’dbo.many’) is not null drop function dbo.many;
go
create function dbo.many (
@top bigint
)
returns table
as
return
select top (@top) 1 as number
from sys.all_columns a,
sys.all_columns b,
sys.all_columns c;
go
if object_id(N’dbo.cons_nos’) is not null drop function dbo.cons_nos;
go
create function dbo.cons_nos (
@top bigint
, @offset bigint
)
returns table
as
return
select row_number() over(order by number) + (@offset – 1) as number
from dbo.many(@top)
go;
[/code]
If you have tried running the solution presented in this post you will most likely realised that there is a limitation with this solution. The size of the result set requested has a profound effect on performance. If you request a very large result set (Say over 100,000,000 records) then you might be waiting a while for the list to return, even on a high end modern server. In any case large result sets will always cost time so this is no different. However storing the required values ahead of time may prove a quicker solution which you should test if you need all the performance you can get.