This is a post about an interesting plan change I noticed while experimenting having attended a presentation by Adam Machanic (Blog) at sqlbits. For anyone who doesn’t know who Adam is I suggest finding any videos of his previous PASS sessions, he is a very clever chap who deals with some unique problems giving him amazing insights into the optimizer. Adam was at sqlbits in the UK, great conference which I highly recommend by the way, talking about row goals. Once that the session is available online I would recommend people watch it. Truly great session about helping the optimizer choose the correct plan without forcing a fragile plan using “hints”. Incidentally this isn’t how I generate my sequential number lists at present, please see this post for my current solution.
If you’ve read my other posts you may have noticed that I don’t do as much development as DBA work. Maybe my posts don’t necessarily bear that out though. In any case I like developing T-SQL and I like to focus on efficiency where I can. There is no reason to leave performance to randomness and we should, in my opinion, attempt to guide the optimiser down the right path in how we write our queries. Now as most of you will know we can “Hint” (Better called force) certain plans with hints. However we can use hints in more subtle ways and this is where I came across a nice plan change while playing with what I learnt from Adam. I have used simpler queries below for illustration. First off the query was based on the below, this gave me the flexibility to change any part of the record set I wanted to as well as the expected row counts (I used SQL Server 2014): –
[code language=”sql”]
declare @i int = 20
, @j int = 20
, @k int = 20;
select row_number() over(order by c.i)
from (
select top (@i)
[object_id]
from sys.all_columns
) c (i)
cross join (
select top (@j)
[object_id]
from sys.all_columns
) d (i)
cross join (
select top (@k)
[object_id]
from sys.all_columns
) e (i);
[/code]
Ordinarily I would not be using the top statements or sub-queries because this is just a nice way to generate a number list (In this case 1 – 8,000). However I put this in a while loop to run 1,000 times to do some performance checking on it. I didn’t run the exact same query because I didn’t want inserts to be the main bottleneck however this query better illustrates what I want to show. The execution time on my Surface Pro 3 was about 5.2 seconds. The plan had a nasty little sort operator in it. I wondered if I could make this disappear.
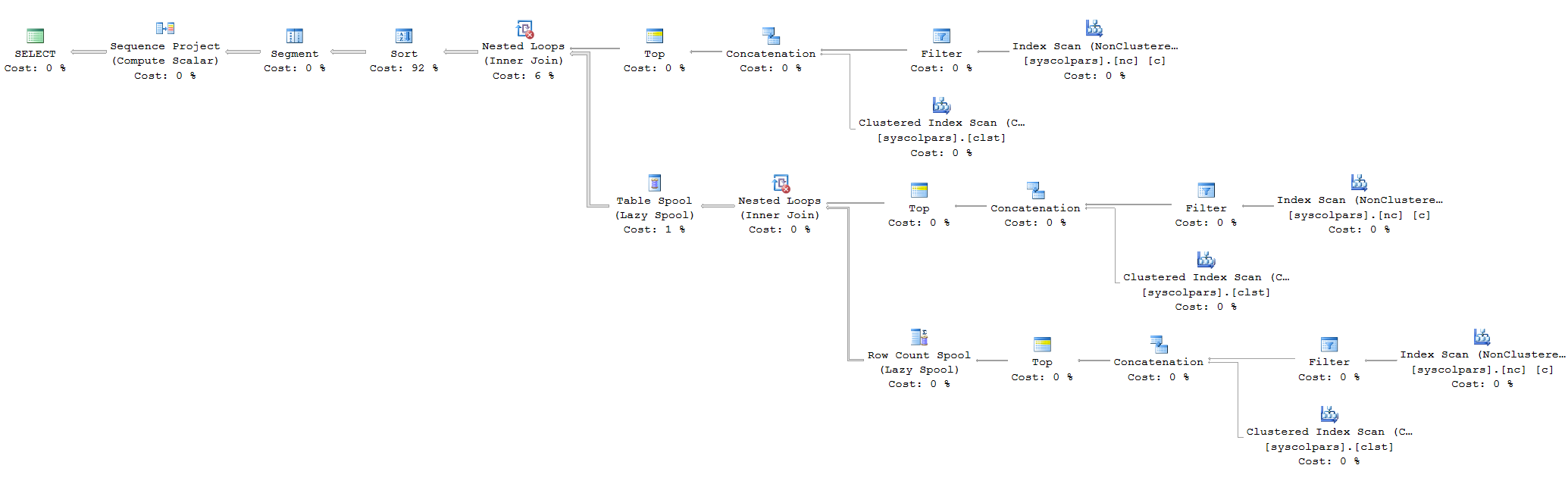
I changed the script to the below (After some playing around with some optimize for values) and got a rather nice improvement in both the plan and the run time. The latter was down to 1 second.
[code language=”sql”]
declare @i int = 20
, @j int = 20
, @k int = 20;
select row_number() over(order by c.i)
from (
select top (@i)
[object_id]
from sys.all_columns
) c (i)
cross join (
select top (@j)
[object_id]
from sys.all_columns
) d (i)
cross join (
select top (@k)
[object_id]
from sys.all_columns
) e (i)
option (optimize for (@i = 40, @j = 30, @k = 30));
[/code]
What struck me was that the first query had a 62MB memory grant and a rather expensive sort that didn’t exist when I hinted larger numbers. However the largest number hinted had to be the first (@i) and also had to exceed the others by a certain value. I tracked this performance improvement down to a merge concatenation as opposed to straight up concatenation. The later being more expensive because it sorts all the records not just the first join (Which is sufficient in this query).
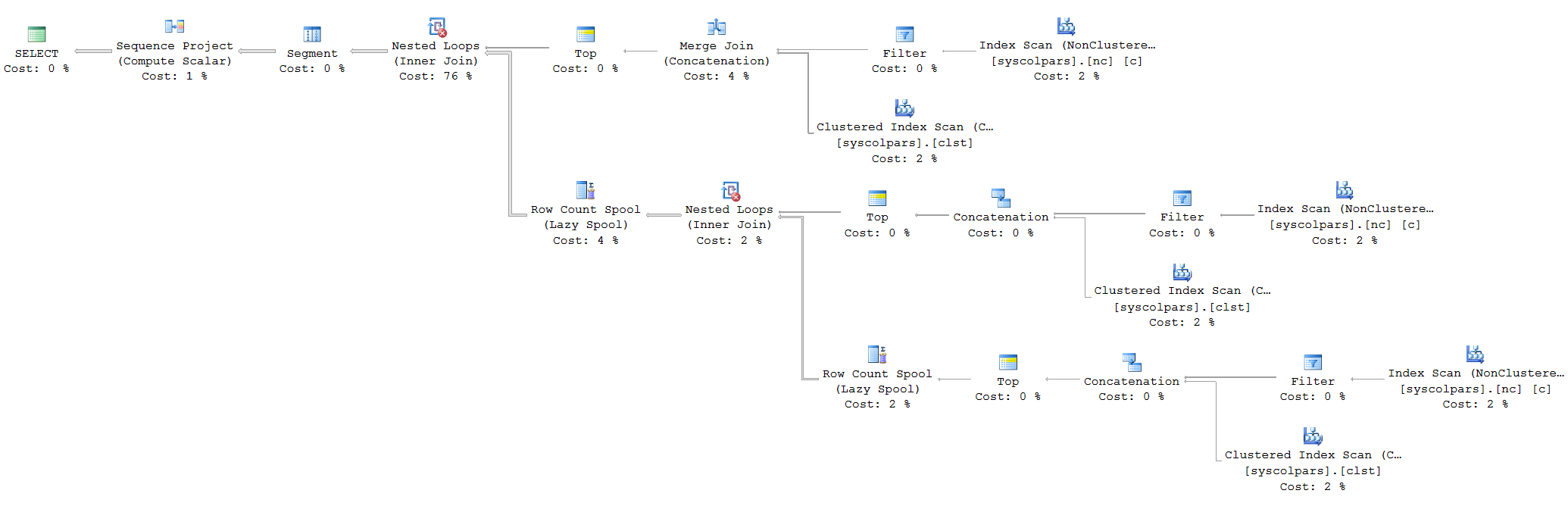
More impressively when I used larger numbers for the declared variables I still needed the hint to benefit from the plan shape I had generated, even when these were identical to the values I was passing in. Again I benefitted massively from not needing a sort space memory grant (Which due to memory limitations on my Surface rapidly spills to disk) and not needing the sort at all. On larger values this was very easily noticeable. The same 5x performance improvement was noticeable for almost any range of values in the declares. However to make them show I did need to use a loop, as described before, because generating 30,000 numbers is near instant. At 27,000,000 the runtime changed between 22 seconds and 4.5 seconds. Again the later was with the optimize for hint.
I would like to finish this post with another big thank you to Adam Machanic and what I learnt at SQLBits. I will be doing some more playing in this area and there may be some more posts to follow.